탐색 알고리즘
- 그래프의 모든 정점들을 특정한 순서에 따라 방문하는 알고리즘
그래프
Graph
1. 그래프의 표현과 정의
grand-jumper-7af.notion.site

그래프 (Graph) : 정점(Vertex)과 간선(Edge)로 구성된, 한정된 자료구조
- 정점(Vertex) : 각각의 지점
- 간선(Edge) : 정점과 정점의 연결
암시적 그래프 표현

- 그래프가 아니지만 그래프 탐색 알고리즘을 활용해 풀 수 있는 문제들이 있음
- 그래프로 표현할 수 있지만 번거로움
- 데이터의 형태에 따라 정점과 간선 대신 x,y 좌표로 각 위치를 표현
Q) 그래프를 통해서 어떤 문제를 풀 수 있을까?
EX) 네비게이션 경로 검색
- 여러 개의 도시와, 도시를 연결하는 도로의 목록이 주어진다.
- 한 도시가 다른 도시와 연결되어 있는지 알 수 있는가?
- 위의 계산을 정해진 시간내에, 효율적으로 할 수 있는가?
EX) 미로에서 경로 찾기
- N x M 크기의 배열로 표현되는 미로가 주어짐
- 미로의 출발점과 도착점은 연결되어 있는가?
- 위의 계산을 정해진 시간 내에, 효율적으로 할 수 있는가?
➡ 탐색 알고리즘이 필요
: 각 정점이 서로 연결되어 있는지 주어진 시간 내에 탐색을 통해 확인하는 알고리즘이 필요
깊이 우선 탐색 [DFS]
DFS
그래프의 탐색 (search) 알고리즘 : 그래프의 모든 정점들을 특정한 순서에 따라 방문하는 알고리즘
grand-jumper-7af.notion.site
- 가장 직관적이고 구현하기 쉬운 탐색 방법
- 현재 정점과 연결된 정점들을 하나씩 갈 수 있는지 검사하고 특정 정점으로 갈 수 있다면 그 정점에 가서 같은 행위를 반복
- 같은 정점을 다시 방문하지 않도록 정점에 방문했다는 것을 표시함
- 재귀 함수를 통해 구현
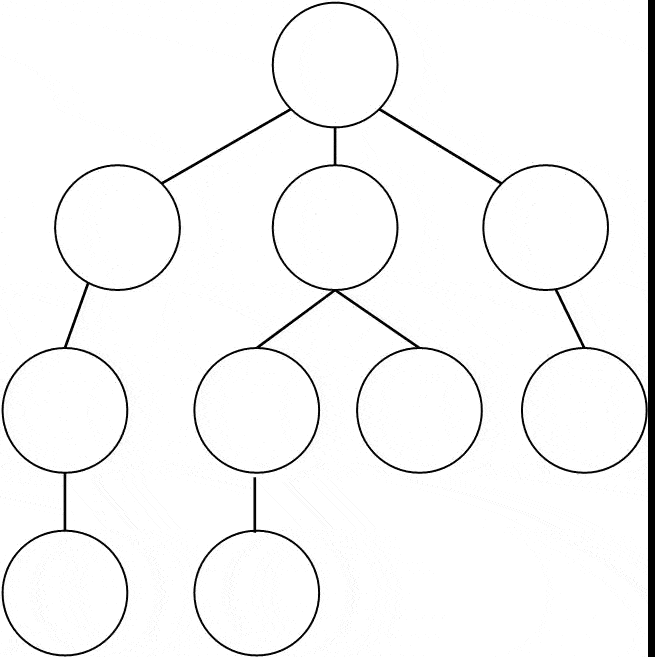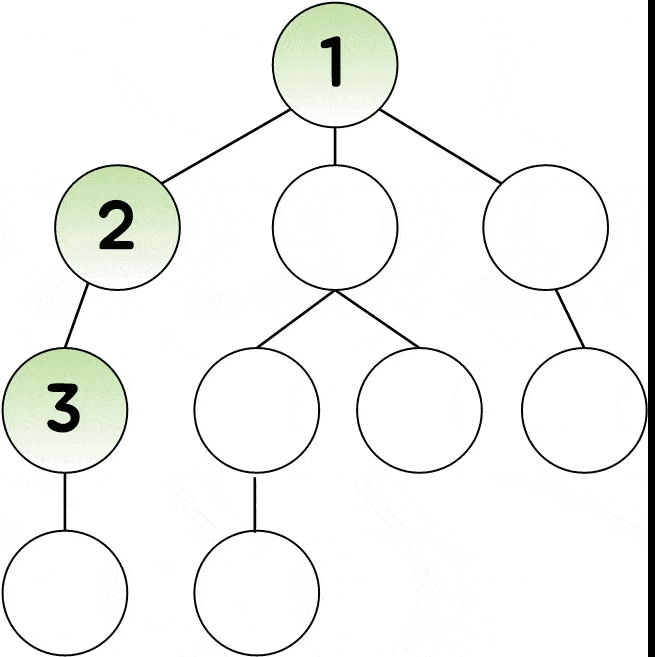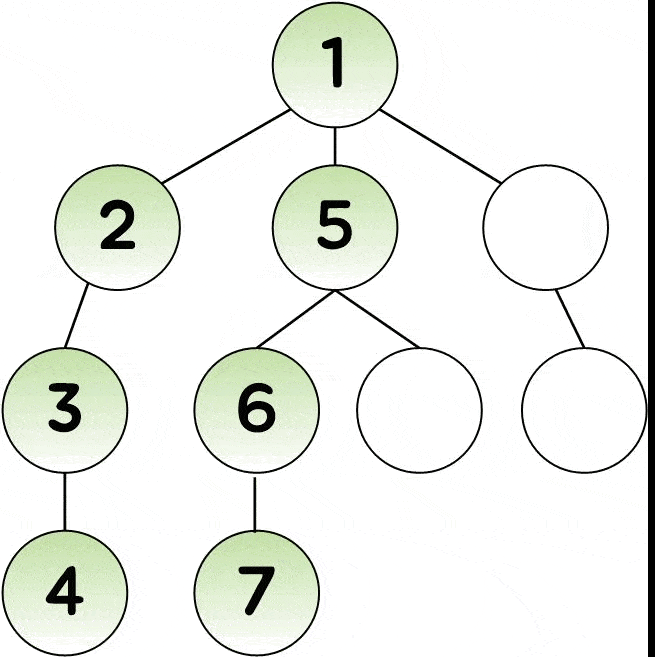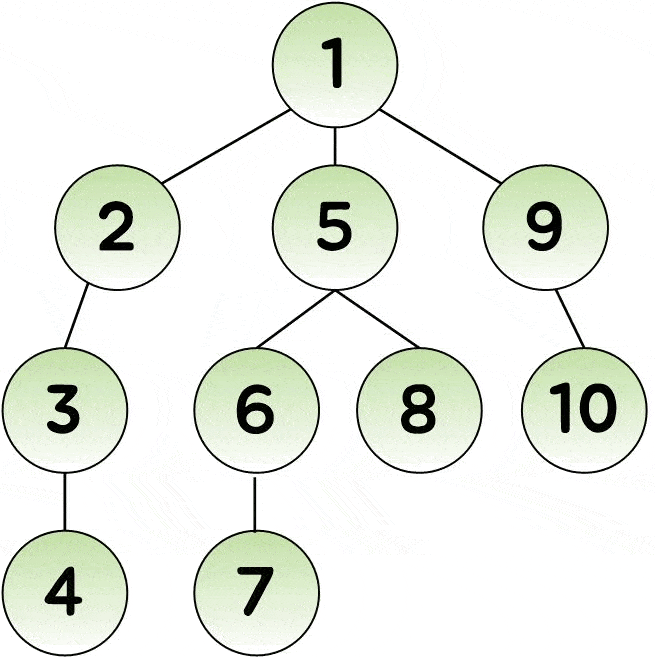
- 시작점에서 한 갈래로 더 이상 갈 수 없을 때 까지 탐색
- 더 갈 곳이 없다면 이전의 경로로 되돌아감
DFS 구현 방법
/**
* visit(nodeId) : ID가 nodeId인 정점을 방문한 것으로 표시
* linkedNode(nodeId) : 현재 정점과 연결된 다른 정점의 목록
* isVisit(nodeId) : ID가 nodeId인 정점을 방문했는지 여부를 반환
*
* @param nodeId 현재 정점을 표시하는 ID 값
*/
void DFS_Graph(int nodeId) {
//방문했다는 것을 먼저 표시
visit(nodeId);
//연결된 그래프들을 확인
for(Node node : linkedNode(nodeId)) {
//아직 방문하지 않은 경우, 재귀적으로 탐색
if(isVist(node.getId()) != true) {
DFS_Graph(node.getId());
}
}
}- DFS_Graph 메소드에 정점(노드)의 id를 전달
- 정점을 방문했다는 것을 처리
- 해당 정점과 연결되어 있는 다른 정점들을 찾아 방문하지 않았다면 재귀적으로 호출
DFS 장점
- 코드가 직관적이고 구현하기 쉬움
DFS 단점
- 재귀함수를 이용하기 때문에 함수 호출 비용이 추가로 들어감
- 재귀 깊이가 지나치게 깊어지면 메모리 비용을 예측하기 어려움
➡ 데이터 사이즈가 일정 이상이면 DFS를 사용하지 않는 것이 좋음 - 최단 거리를 알 수 없음
너비 우선 탐색 [BFS]
BFS
3. 그래프의 너비 우선 탐색
grand-jumper-7af.notion.site
- 시작점에서 가까운 정점부터 순서대로 방문하는 탐색 알고리즘
- 큐를 이용하여 구현
- 출발점을 먼저 큐에 넣고, 다음 로직을 반복
- 큐에 저장된 정점을 하나 Dequeue
- Dequeue된 정점과 연결된 모든 정점을 큐에 넣음
- 큐가 비어있다면 반복을 종료

- 시작점 기준으로 거리가 1인 모든 지점을 탐색
거리가 2인 모든 지점 탐색
거리가 3인 모든 지점 탐색
➡ 반복 - 목표지점을 찾으면 탐색을 종료
- 찾지 못했다면 연결된 모든 지점을 탐색
BFS 구현 방법
/**
* visit(nodeId) : ID가 nodeId인 정점을 방문한 것으로 표시
* isVisit(nodeId) : ID가 nodeId인 정점을 방문했는지 여부를 반환
* targetId : 목적지의 ID 값
*
* @param startNodeId 출발한 정점의 ID 값
*/
void BFS_Graph(int startNodeId) {
//시작 지점을 먼저 넣어준다.
queue.push(startNodeId);
while(queue.isNotEmpty()) {
//위치를 하나 뽑아, 방문 처리를 해준다.
Long nodeId = queue.pop();
visit(nodeId);
if(targetId.equals(node.getId())) {
return;
}
//연결된 다른 정점들을 순회한다.
for(Node node : linkedNode(nodeId)) {
if(isVist(node.getId()) != true) {
queue.push(node.getId());
}
}
}
}- 시작점을 큐에 넣고 이후 큐가 빌 때까지 루프를 돌림
- 큐의 제일 앞에 있는 정점을 뽑음
- 뽑은 지점과 연결된 정점을 큐에 추가
- 뽑은 지점이 목표 정점이라면 루프 종료
- 만약 목표 지점을 찾지 못해도 더 갈 수 있는 지점이 없으면 루프 종료
BFS 장점
- 효율적인 운영이 가능
- 시간/공간 복잡도 면에서 안정적
- 간선의 비용이 모두 같을 경우 최단 경로를 구할 수 있음
*간선의 비용이 각각 다를 경우, 다익스트라 알고리즘 등의 최단거리 알고리즘을 활용해야 함
BFS 단점
- DFS에 비해 코드 구현이 어려움
- 모든 지점을 탐색할 경우를 대비해 큐의 메모리가 미리 준비되어 있어야 함
참고문헌
1) [10분 데코톡] 📚카프카의 탐색 알고리즘
2) 구종만, 『프로그래밍 대회에서 배우는 알고리즘 문제 해결 전략』, 인사이트 (2012)